\zs, ze, modify the start or end of regex
match, can make replacing or searching easier
\zs can replace positive look
behind@<=\ze can replace positive look ahead
@=\_. matches all characters and end of
line, useful for multiline matching
. matches all characters but not end of line\w matches word characters, same as
[0-9A-Za-z_]\s matches space or tab\{-} non-greedy match, match as little as possible,
this is a multi
*Intresting Examples
\(def\s\)\@<!foo_function(\_.\{-}) matches function
usage and params single line or multi lines, but not
the function definitiondef\s\w*(\zs\_.\{-}\ze) matches only params in function
definitions, single line or multi linesa an ordinary character,
\i a character class, \(foo\) putting
pattern in parenthesis making it an atom*, \{n,m},
{-}
\@=,
\@!, look behind
\@<=,\@<!,a*b*\&
concat, \& means matching both regex
patterns, like AND\|
branch, \| means either patterns, like
OR| Rg | Vim | |
|---|---|---|
| zero or more | ? |
\? |
| 1 or more | + |
\+ |
| precise number of matches | {n,m} |
\{n,m} |
| word boundary | \b |
\< \> |
| multiple patterns or | | |
\| |
| non greedy | .*? |
.\{-} |
| line starts with | ^ |
^ |
| line ends with | $ |
$ |
| group | ( ) |
\( \) |
| back reference | not supported | \1 \2 \3 |
Example: to match company and companies
compan\(y\|ies\)compan(y|ies)var# vim9script reminder
# use `var` to define variable, instead of `let`
# boolean
true
false
# option value &foo
echo &number
# assigns value to option
&number = 1
# contents of register `q`
echo @q
# remove or set contents of register `q`
@q = ""
# set register q in linewise mode
setreg('q', '', 'V')
# string concatenation
var foo = "abc" .. "def"
# string interpolation
var name = "tiger"
echo $"hello {name}!"
# setting variable name to register
# @0 is last yanked text
var name = @0
# list
var foo_list = [1, 2, 3]
var first_item = foo_list[0]
var first_two_items = foo_list[0 : 2]
var last_two_items = foo_list[-2 : ]
# list concatenation
var foo_list_extended = foo_list + [4, 5]
# builtin list methods
mylist->add(val1)->add(val2)
mylist->copy()
mylist->count(val)
mylist->empty()
mylist->extend(otherlist)
mylist->filter(expr2)
mylist->flatten()
mylist->foreach(expr2)
mylist->indexof(expr)
mylist->insert(item)
mylist->join()
mylist->len()
mylist->map(expr2)
mylist->max()
mylist->min()
mylist->remove(idx)
mylist->repeat(count)
mylist->reverse()
mylist->sort()
mylist->string()
mylist->type()
mylist->uniq()
# dictionary
var foo = {"a": 1, "b": 2, "c": 3}
echomsg foo["a"]
for [key, value] in foo->items()
echomsg key value
endfor
# dictionary methods
mydict->has_key(key)
mydict->items()
mydict->keys()
mydict->values()
# if
var a = 1.5
if a > 2
echo "a > 2" a
elseif a > 1
echo "a > 1" a
else
echo "a < 1" a
endif
# for loop
var foo = [1, 2, 3]
for i in foo
echo i
endfor
# regex match, right hand side string is used as a pattern
# echo true
echo "foo" =~ '^f.*'
# echo false
echo "foo" =~ 'b.*'
# powerful commands
# execute the string from the evaluation of {expr1} as an cli # command
execute "normal @q"
# calling vim builtin function, see `:help builtin.txt`
# see help for builtin function `substitute` at `:help substitude()`
var remove_prefix = substitute(posix_file_path, '^saltus/', '', 'g')
# Types
float, string, bool, number, float, string, blob, list<type>, dict<type>, job,
channel, funcdef GetWordAfterPrefix(prefix_string: string): string
# search for the line number and column number for the prefix_string
# e.g. the line and column of character 'f' in `def \zsfoo`
# flag `b` - search backward
# flag `n` - do not move the cursor
# see also `:help search()`
var [match_line_number, match_col_number] = (prefix_string .. '\zs')->searchpos('bn')
var line = getline(match_line_number)
# get the word with matching column position - 1, `-1` is needed to include
# the first character of the word, e.g. word would be `foo`
var word = line->matchstr('\w*', match_col_number - 1)
return word
enddef
def g:YankWordAfterPrefix(prefix_string: string)
var word = GetWordAfterPrefix(prefix_string)
echom 'yanked' word
setreg('+', word)
enddef
nnoremap <leader>yf :call YankWordAfterPrefix("def ")<cr>
nnoremap <leader>yc :call YankWordAfterPrefix("class ")<cr>
def GetPythonFileImportPath(): string
var posix_file_path = expand("%")
var python_import_path = posix_file_path
->substitute('^saltus/', '', 'g')
->substitute('.py$', '', 'g')
->substitute('/', '.', 'g')
return python_import_path
enddefdef g:JumpToTestFile()
py3 << EOF
from vim_python import get_or_create_alternative_file
# vim.eval("@%") gets the filepath in current buffer
test_filepath = get_or_create_alternative_file(filepath=vim.eval("@%"))
# open test_filepath in current window
vim.command(f"tabnew {test_filepath}")
EOF
enddef> cat foo.vim
vim9script
var a = [1, 2, 3]
echomsg a
> vim -S foo.vim:cexpr system('command that returns quickfix format')vim -q <(command that returns quickfix error format)Example for quickfix format
./lambdas/atr_notification/__init__.py:1:1: F401 'json' imported but unused
./lambdas/atr_notification/__init__.py:2:1: F401 'boto3' imported but unused
./lambdas/atr_notification/__init__.py:4:1: F401 'lambdas.common.config.oneview.SNS_TARGET_ARN' imported but unused:verbose nmap ]] - to find out which file that mapping
is defined in. From there you should be able to figure out which plugin
that file is a part ofUseful resources on how to do mappings below
https://vim.fandom.com/wiki/Mapping_keys_in_Vim_-Tutorial(Part_2)
https://learnvimscriptthehardway.stevelosh.com/chapters/30.html
:py3 import os;print(os.__file__) - print path of
python
For example, I want to match on the second < of the
following line
cnoremap <c-j> <down>
cnoremap <c-k> <up>
cnoremap <up> <nop>
cnoremap <down> <nop>
cnoremap <left> <nop>
cnoremap <right> <nop>Uses pattern <.*\zs<
< - matches the first <.* - greedy matches everything after\zs - resets the start of the pattern matches (a vim
specific pattern)< - matches the second <Bonus:
sed -n 's/<.*\(<\)/\1/p' changes
cnoremap <c-j> <down> to
cnoremap <down>, something like delete the first
<>
sed -n 's/\(<.*\)<.*>/\1/p' changes
cnoremap <c-j> <down> to
cnoremap <c-j>, something like delete the second
<>
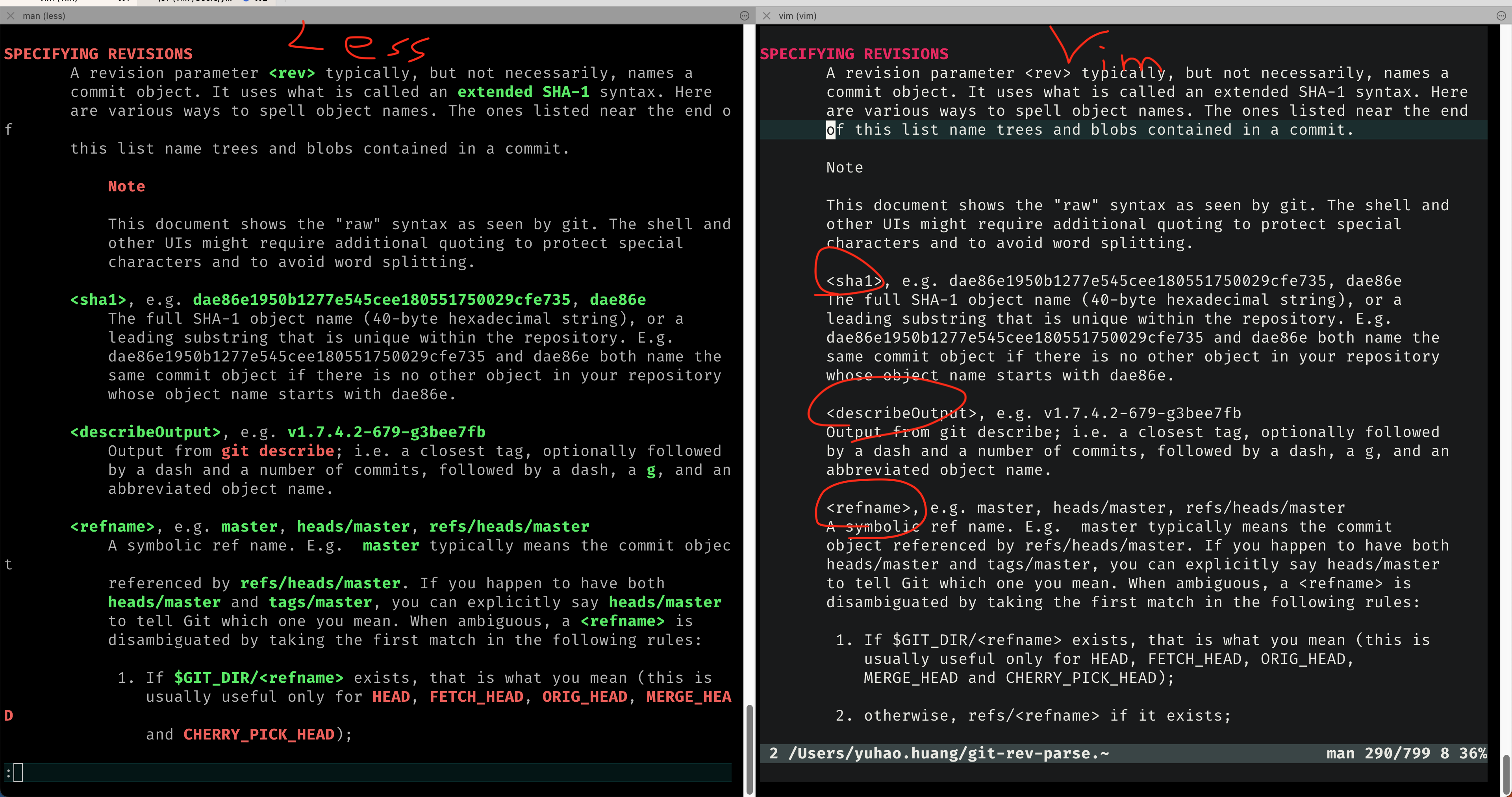
Vim with :Man, you will need
runtime ftplugin/man.vim:Man dateexport MANWIDTH=80, this sets the width to 80
so that the man page can fit in one page with correct paragraph
indent:TOhtml (P.S. I have my own
:TOPrintHtml)ZSHMISC(1) General Commands Manual ZSHMISC(1)
NAME
zshmisc - everything and then some
SIMPLE COMMANDS & PIPELINES
A simple command is a sequence of optional parameter assignments followed
...
PRECOMMAND MODIFIERS
A simple command may be preceded by a precommand modifier, which will
...I would like the extract a Table of Content from manual page such as below
SIMPLE COMMANDS & PIPELINES
PRECOMMAND MODIFIERS:redir @a - setup redirect to register
a:g/^\u.*/p - find all lines start with upper case and
print them:redir END - end the redirection"ap - paste content in register a:py3 print('abc')
# to change lines in range
:'<,'>py3do return line.split(":")[0] + ' = ' + line.split(":")[0].strip() + ','
# run foo.py in current directory, have access to all vim_python objects
# see `:help python-command`
:pyfile foo.py
# For example
#
# > cat foo.py
# vim.command('buffers a')
# for b in vim.buffers:
# print(b)
# print(b.__dir__())
# print(b.valid)
# visible_buffers = [window.buffer for window in vim.current.tabpage.windows]"kp - paste from register k
"Kyy - append to register k by using capital
register letter K
"0p - paste from last yanked test
qk - start to record macro in register
k
[count]@k - apply macro in register k,
[count] number of times
@@ - apply last macro
:g/foo/d - delete lines with pattern foo in this file,
d is the abbreviation of :delete command:g/foo/normal Q - apply macro on lines with pattern foo
in this filevim.eval in vim pythondef get_import_path_given_word(vim: object) -> str | None:
word = vim.eval('expand("<cword>")')
for package, words in package_and_word.items():
if word in words:
import_string = f"from {package} import {word}"
print(import_string)
return import_stringThis function above is used in vim_python.py imported
into vim.
The vim.eval literally runs the string passed in as vim
code and export the vim object into python object
For example, the following two vim commands are equivalent.
:py3 print(vim.eval('expand("<cword>")'))
:echom expand("<cword>")See also :help if_pyth.txt # regex look ahead /
behind
Find expression A where expression B follows
\@= e.g. \A\(B\)\@=
might be easier to use \ze
Find expression A where expression B does not follow
\@! e.g. A\(B\)\@!
Find expression A where expression B is behind:
\@<= e.g. \(B\)\@<=A
might be easier to use \zs
Find expression A where expression B is not behind:
\@<! e.g. \(B\)\@<!A
For example
foo(
def foo(to match only function definitions, e.g. the foo after
def
\(def[ ]\)\@<=foo(
to match function usage e.g. the foo not after
def
\(def[ ]\)\@<!foo(
foobar
foobazfoo\(bar\)\@= - matches foo that follows with bar
e.g. matches first
foo\(bar\)\@! - matches foo that not follows with bar
e.g. matches second
I learn that I should enable my true color support which makes molokai color theme much better to see.
set termguicolors
Useful links
Test your terminal color molokai color scheme
Vim doesn’t intepret ansi sequences good enough, see the following photo.
gq formatoptionCurrent formatoption for markdown is formatoption=jtln
from set formatoptions?
*fo-j*j Where it makes sense, remove a comment leader when joining lines. For example, joining: int i; // the index ~ // in the list ~ Becomes: int i; // the index in the list ~
*fo-t*t Auto-wrap text using ‘textwidth’
*fo-l*l Long lines are not broken in insert mode: When a line was longer than ‘textwidth’ when the insert command started, Vim does not automatically format it.
*fo-n*n When formatting text, recognize numbered lists. This actually uses the ‘formatlistpat’ option, thus any kind of list can be used. The indent of the text after the number is used for the next line. The default is to find a number, optionally followed by ‘.’, ‘:’, ‘)’, ‘]’ or ‘}’. Note that ‘autoindent’ must be set too. Doesn’t work well together with “2”. Example: > 1. the first item wraps 2. the second item